Les index B-tree
L’index B-tree est une arborescence ordonnée composée de nœuds d'index. Il contient une entrée par enregistrement. Il existe des index créés automatiquement pendant la création d’une contrainte de type « PRIMARY KEY » ou « UNIQUE ». En effet, ce sont des index uniques, l’unicité étant gérée par Oracle à travers des index.
Il est possible de créer un index de ce type uniquement si les valeurs du ou des champs qui composent l’index sont uniques sur l’ensemble des valeurs de la table.

SQL> CREATE UNIQUE INDEX SINDX_COMM_EMPLOYE_UK ON
2 SINDX_COMMANDES (NO_EMPLOYE) TABLESPACE INDX_TP;
SINDX_COMMANDES (NO_EMPLOYE) TABLESPACE INDX_TP;
*
ERREUR à la ligne 2 :
ORA-01452: CREATE UNIQUE INDEX impossible ; il existe des doublons
![]() A partir de la version Oracle 12c cette restriction n’est plus valable, vous pouvez utiliser le même ensemble de colonnes pour un index de type b-tree et pour un index bitmap. Mais attention un seul de ces index est visible à la fois.
A partir de la version Oracle 12c cette restriction n’est plus valable, vous pouvez utiliser le même ensemble de colonnes pour un index de type b-tree et pour un index bitmap. Mais attention un seul de ces index est visible à la fois.
STAG01@topaze>select ic.table_name,index_name,i.index_type,ic.column_name
2 from user_ind_columns ic join user_indexes i using(index_name)
3 where ic.table_name = 'COMMANDES' and ic.column_name = 'NO_EMPLOYE';
TABLE_NAME INDEX_NAME INDEX_TYPE COLUMN_NAME
---------- -------------------- ---------- --------------------
COMMANDES COMM_EMPL_FK NORMAL NO_EMPLOYE
STAG01@topaze>create bitmap index comm_empl_bmp on commandes ( no_employe);
on commandes ( no_employe)
*
ERREUR à la ligne 2 :
ORA-01408: cette liste de colonnes est déjà indexée
STAG01@topaze>alter index comm_empl_fk invisible;
Index modifié.
STAG01@topaze>create bitmap index comm_empl_bmp on commandes ( no_employe);
Index créé.
STAG01@topaze>select ic.table_name,index_name,i.index_type,ic.column_name
2 from user_ind_columns ic join user_indexes i using(index_name)
3 where ic.table_name = 'COMMANDES' and ic.column_name = 'NO_EMPLOYE';
TABLE_NAME INDEX_NAME INDEX_TYPE COLUMN_NAME
---------- -------------------- ---------- --------------------
COMMANDES COMM_EMPL_BMP BITMAP NO_EMPLOYE
COMMANDES COMM_EMPL_FK NORMAL NO_EMPLOYE
La façon la plus rapide d’accéder aux données d’une table est d’utiliser la valeur du « ROWID » de l’enregistrement que vous voulez afficher. Mais attention, rappelez-vous que lorsque vous réorganisez une table, la valeur des « ROWID » des enregistrements est modifiée. La deuxième manière est d’utiliser un index pour arriver au même résultat.
Par nature, un index comprend un certain volume d'informations dont le coût de traitement peut dépasser celui d'un balayage complet séquentiel d'une table, selon le nombre de blocs qu'il faut lire dans la table pour renvoyer la ligne pointée par le « ROWID » de l'index.
STAG@agate>set autotrace trace
STAGB@agate>select * from commandes
2 where no_commande between 260000 and 300000;
40001 ligne(s) sélectionnée(s).
----------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| COMMANDES |
|* 2 | INDEX RANGE SCAN | COMMANDES_PK |
----------------------------------------------------
Statistiques
----------------------------------------------------------
0 recursive calls
0 db block gets
5894 consistent gets
...
STAGB@agate>select * from commandes
2 where no_commande between 250000 and 300000;
50001 ligne(s) sélectionnée(s).
---------------------------------------
| Id | Operation | Name |
---------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS FULL| COMMANDES |
---------------------------------------
Statistiques
----------------------------------------------------------
1 recursive calls
0 db block gets
5869 consistent gets
...
Dans l’exemple précédent vous pouvez voir dans le plan d’exécution « TABLE ACCESS FULL », ce qui signifie que l’ensemble des blocs du HWM de la table est lu, pour retrouver l’information. Mais le nombre des blocs lus pour afficher les enregistrements de la deuxième requête est inférieur au nombre des blocs lus par la première requête qui utilise elle l’index de clé primaire.
À partir de la version Oracle 11g, il est possible de créer un index et de le rendre invisible pour les requêtes des utilisateurs. C’est une option très interesante pour tester la pertinance de la mise en œuvre de l’index.
Ainsi vous pouvez créer un index et tester les requêtes, il sufit de modifier le paramètre de votre session « OPTIMIZER_USE_INVISIBLE_INDEXES ». Par la suite pour toutes les requêtes de votre session, l’optimiseur utilise cet index vous permetant d’efectuer les tests necessaires. Finalement vous pouvez rendre l’index visible pour toutes les autres sessions ou l’effacer.
STAG@agate>alter index COMMANDES_PK invisible;
Index modifié.
STAG@agate>select * from commandes
2 where no_commande between 260000 and 280000;
---------------------------------------
| Id | Operation | Name |
---------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS FULL| COMMANDES |
---------------------------------------
STAG@agate>alter session set optimizer_use_invisible_indexes=true;
Session modifiée.
STAG@agate>select * from commandes
2 where no_commande between 260000 and 280000;
----------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| COMMANDES |
|* 2 | INDEX RANGE SCAN | COMMANDES_PK |
----------------------------------------------------
L’utilisation d’index B-tree
L'index B-tree est le type d'index le plus courant, et celui utilisé par défaut. Un index B-tree stocke la valeur de clé et le « ROWID » de chaque enregistrement de la table.
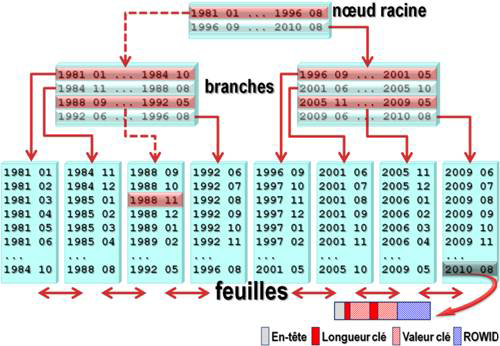
La structure d'un index B-tree comprend trois types de niveaux :
Le bloc racine est le point de départ et il contient les entrées qui pointent vers le niveau suivant dans l'index.
Les blocs branches contiennent l’information pour diriger la recherche vers les blocs du niveau suivant de l'index.
Les blocs feuilles contiennent les entrées d'index qui pointent vers les enregistrements d'une table. Une liste doublement chaînée gère l’ensemble des blocs feuilles pour que vous puissiez facilement parcourir l'index dans l'ordre croissant ou décroissant des valeurs de clé.
Un enregistrement dans un bloc feuille possède la structure suivante :
L’en-tête qui contient le nombre de champs et les informations de verrouillage.
Pour chaque champ qui compose l’index, la taille de la colonne clé et la valeur de cette colonne.
Le « ROWID » de l’enregistrement correspondant.

La recherche des données est effectuée avec les pas suivants :
1. La recherche démarre avec le bloc racine.
2. Rechercher dans un bloc branche l’enregistrement qui a une valeur de clé « CLE » plus grande ou égale à la valeur cherchée « VALEUR ».
CLE ≥ VALEUR
3. Si la valeur clé trouvée est supérieure à la valeur cherchée, suivre l’enregistrement précédent dans le bloc branche vers le niveau inférieur.
CLE > VALEUR
4. Si la valeur de clé trouvée est égale à la valeur cherchée, suivre le lien vers le niveau inférieur.
CLE = VALEUR
5. Si la valeur de clé trouvée est inférieure à la valeur cherchée, alors suivre le lien de l’enregistrement suivant vers le niveau inférieur.
CLE < VALEUR
6. Si le bloc du niveau inférieur est un bloc de type branche, répétez les opérations à partir de l’étape 2.
7. Recherche dans le bloc feuille de la valeur clé égale à la valeur cherchée.
8. Si la valeur est trouvée, alors il retourne « ROWID ».
CLE = VALEUR
return ROWID
8. Si la valeur n’est pas trouvée, alors l’enregistrement n’existe pas.
Les étapes de recherche du mois de novembre de l’année « 1988 11 » dans l’index précédent sont :
Dans le bloc racine qui est un bloc de type branche, on recherche « CLE ≥ VALEUR ».
'1996 09' > '1988 11'
La clé trouvée « 1996 09 » est supérieure à la valeur cherchée « 1988 11 ». Suivez l’enregistrement précédent dans le bloc branche vers le niveau inférieur. Le bloc du niveau inférieur contient les enregistrements « 1981 01 », « 1984 11 », « 1988 09 » et « 1992 06 ».
La recherche recommence à partir de l’étape « 2 ». Dans le bloc branche, on recherche « CLE ≥ VALEUR ».
'1992 06' > '1988 11'
La clé trouvée « 1992 06 » est supérieure à la valeur cherchée « 1988 11 ». Suivre l’enregistrement précédent dans le bloc branche vers le niveau inférieur. L’enregistrement précédent est « 1988 09 » et il conduit à un bloc feuille.
La valeur cherchée « 1988 11 » est trouvée, alors elle retourne « ROWID » correspondant.
STAG@agate>set autotrace on exp
STAG@agate>select * from dim_temps where JOUR = '01/01/2010';
JOUR SEMAINE MOIS MOIS_N TRIMESTRE ANNEE
---------- ------- -------- ------ ---------- ----------
01/01/2010 53 Janvier 1 1 2010
Plan d'exécution
------------------------------------------------------------
| Id | Operation | Name | Rows |
------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 |
| 1 | TABLE ACCESS BY INDEX ROWID| DIM_TEMPS | 1 |
|* 2 | INDEX UNIQUE SCAN | DIM_TEMPS_PK | 1 |
------------------------------------------------------------
Avantages et inconvénients
Les index sont surtout utiles sur de grandes tables et sur des champs susceptibles d'apparaître dans des clauses « WHERE » avec une condition d'égalité.
Les données sont extraites plus rapidement à partir des champs indexés lorsqu'elles sont mentionnées dans des clauses « WHERE », sauf lorsque les opérateurs « IS NOT NULL » et « IS NULL » sont spécifiés.
Attention, si vous avez créé un index sur un ou plusieurs champs, il faut s’assurer que dans les clauses « WHERE » les champs sont utilisés directement sans faire partie des expressions car dans ce cas l’index n’est pas utilisé.
Conseils pour définir vos index :
Ne pas créer d'index pour des tables de petite taille. Le gain de vitesse de recherche n'est pas supérieur au temps d'ouverture et de recherche dans l'index.
Ne pas créer d'index de type B-tree sur des champs avec peu de valeurs distinctes.
Ne pas créer d'index si la plupart de vos requêtes ramènent plus de 25% des enregistrements.
Ne pas créer beaucoup d'index sur une table fréquemment mise à jour.
En cas de sélections fréquentes effectuées sur un champ avec une condition unique, créer un index sur cette colonne.
En cas de jointures fréquentes effectuées entre deux champs de deux tables, créer un index sur ce champ.
Cependant il est recommandé de ne pas abuser des index car :
Les index utilisent de l'espace disque supplémentaire ; ceci est très important lors des sélections sur plusieurs tables avec des index importants car la mémoire centrale nécessaire sera également accrue.
La modification des champs indexés dans la table entraîne une éventuelle mise à jour de l'index. De ce fait, les index alourdissent le processus de mise à jour des valeurs d'une table relationnelle.
Les index d’arbre équilibré sont les plus couramment utilisés dans les bases de données transactionnelles.
Les cas d’utilisation
Les index de type B-tree peuvent être pris en compte dans les plans d’exécution dans plusieurs cas ; par la suite on va exemplifier les plus courantes.
Les index de fonction
L’utilisation d’une expression qui contient le champ indexé dans la clause « WHERE » exclut l’utilisation de l’index. Voici la table « COMMANDES » avec un index sur le champ « DATE_COMMANDE » ; l’index n’est pas utilisé si le champ est dans une expression.
STAG@agate>create index commandes_date_commande
2 on commandes (date_commande) tablespace itp_star;
Index créé.
STAG@agate>select * from commandes
2 where date_commande between '01/08/2009' and '31/08/2009';
---------------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| COMMANDES |
|* 2 | INDEX RANGE SCAN | COMMANDES_DATE_COMMANDE |
---------------------------------------------------------------
STAG@agate>select * from commandes
2 where extract(year from date_commande)=2009
3 and extract(month from date_commande) = 8;
---------------------------------------
| Id | Operation | Name |
---------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS FULL| COMMANDES |
---------------------------------------
STAG@agate>create index commandes_annee_mois
2 on commandes (extract ( year from date_commande),
3 extract ( month from date_commande))
4 tablespace itp_star;
Index créé.
STAG@agate>select * from commandes
2 where extract(year from date_commande)=2009
3 and extract(month from date_commande) = 8;
------------------------------------------------------------
| Id | Operation | Name |
------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| COMMANDES |
|* 2 | INDEX RANGE SCAN | COMMANDES_ANNEE_MOIS |
------------------------------------------------------------
INDEX UNIQUE SCAN
La clause « WHERE » comporte une égalité avec une clé primaire ou sur un index de type « UNIQUE » ; l'optimiseur utilise alors ce type de parcours d’index.
STAG@agate>select * from employes where no_employe = 40;
---------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYES |
|* 2 | INDEX UNIQUE SCAN | EMPLOYES_PK |
---------------------------------------------------
INDEX RANGE SCAN ou INDEX RANGE SCAN DESCENDING
Le parcours de l’index est effectué de cette manière si vous recherchez un palier de valeurs dans l’ensemble des valeurs de l’index. La recherche peut être exécutée dans l’ordre de l’index ou dans l’ordre inverse.
STAG@agate>select * from employes where no_employe > 40;
---------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYES |
|* 2 | INDEX RANGE SCAN | EMPLOYES_PK |
---------------------------------------------------
STAG@agate>select * from indicateurs
2 where commande = '01/08/2009'
3 and ref_produit = 1 and code_client = 'RANCH'
4 and no_fournisseur = 11 and no_employe > 80
5 order by no_employe desc;
-------------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID | INDICATEURS |
|* 2 | INDEX RANGE SCAN DESCENDING| INDICATEURS_PK |
-------------------------------------------------------
INDEX FULL SCAN et INDEX FAST FULL SCAN
Ce type de parcours d’index est choisi lorsqu'une instruction n'a pas de clause « WHERE » mais que la ou les champs à afficher sont dans l’index, pour éviter de parcourir les blocs de données.
STAG@agate>select no_commande, ref_produit
2 from details_commandes order by no_commande;
-------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | INDEX FULL SCAN | DETAILS_COMMANDES_PK |
-------------------------------------------------
STAG@agate>select count(*) from employes;
----------------------------------------
| Id | Operation | Name |
----------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
| 2 | INDEX FULL SCAN| EMPLOYES_PK |
----------------------------------------
STAG@agate>select no_commande from commandes;
---------------------------------------------
| Id | Operation | Name |
---------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | INDEX FAST FULL SCAN| COMMANDES_PK |
---------------------------------------------
INDEX SKIP SCAN
Est utilisé pour un index avec plusieurs champs si dans votre requête vous ne prenez pas en compte tous les champs de l’index, généralement le premier. Ce parcours d’index est effectué également si vous recherchez des valeurs disparates dans chacun des champs indexés.
STAG@agate>select index_name,column_name, column_position
2 from user_ind_columns
3 where index_name = 'INDICATEURS_PK';
INDEX_NAME COLUMN_NAME COLUMN_POSITION
-------------------- ---------------- ---------------
INDICATEURS_PK COMMANDE 1
INDICATEURS_PK CODE_CLIENT 2
INDICATEURS_PK REF_PRODUIT 3
INDICATEURS_PK NO_FOURNISSEUR 4
INDICATEURS_PK NO_EMPLOYE 5
STAG@agate>select * from indicateurs
2 where ref_produit between 1 and 20 and code_client = 'DRACD'
3 and no_fournisseur = 2 and no_employe = 4;
------------------------------------------------------
| Id | Operation | Name |
------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| INDICATEURS |
|* 2 | INDEX SKIP SCAN | INDICATEURS_PK |
------------------------------------------------------
STAG@agate>select * from indicateurs
2 where code_client = 'DRACD'
3 and no_fournisseur = 2 and no_employe = 4;
------------------------------------------------------
| Id | Operation | Name |
------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| INDICATEURS |
|* 2 | INDEX SKIP SCAN | INDICATEURS_PK |
------------------------------------------------------
STAG@agate>select * from indicateurs
2 where commande between '01/01/2008' and '01/01/2009'
3 and ref_produit between 1 and 3
4 and code_client in ('DRACD','RANCH','RANCH','MORGK')
5 and no_fournisseur in ( 2,7,8,11,20,23)
6 and no_employe in (4,6,40,85,101);
------------------------------------------------------
| Id | Operation | Name |
------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| INDICATEURS |
|* 2 | INDEX SKIP SCAN | INDICATEURS_PK |
------------------------------------------------------
Les données sont extraites plus rapidement à partir des champs indexés lorsqu'elles sont mentionnées dans des clauses « WHERE », sauf lorsque les opérateurs « IS NOT NULL » et « IS NULL » sont spécifiés. Ainsi vous pouvez utiliser les propriétés de « INDEX SKIP SCAN » pour palier cet inconvénient.
STAGB@rubis>SELECT COUNT(*) FROM IND02 WHERE ENVOI IS NULL;
COUNT(*)
----------
25
STAGB@rubis>CREATE INDEX IND02_BTR_ENVOI ON IND02 (ENVOI);
Index créé.
STAGB@rubis>SET AUTOTRACE TRACE EXP
STAGB@rubis>SELECT * FROM IND02 WHERE ENVOI IS NULL;
Plan d'exécution
-------------------------------------------
| Id | Operation | Name | Rows |
-------------------------------------------
| 0 | SELECT STATEMENT | | 25 |
|* 1 | TABLE ACCESS FULL| IND02 | 25 |
-------------------------------------------
STAGB@rubis>DROP INDEX IND02_BTR_ENVOI ;
Index supprimé.
STAGB@rubis>CREATE INDEX IND02_BTR_ENVOI ON IND02 (ENVOI,1);
Index créé.
STAGB@rubis>SET AUTOTRACE TRACE EXP
STAGB@rubis>SELECT * FROM IND02 WHERE ENVOI IS NULL;
Plan d'exécution
----------------------------------------------------------------
| Id | Operation | Name |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| IND02 |
|* 2 | INDEX RANGE SCAN | IND02_BTR_ENVOI |
----------------------------------------------------------------
BITMAP CONVERSION FROM ROWIDS
Dans le cas où une table a plusieurs index de type B-tree, l’optimiseur peut convertir à la volée le résultat de l’interrogation d’un index en index bitmap pour le combiner avec un autre index bitmap obtenu de la même manière.
STAG@agate> select * from commandes
2 where code_client ='RANCH' and no_employe =40;
---------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID | COMMANDES |
| 2 | BITMAP CONVERSION TO ROWIDS | |
| 3 | BITMAP AND | |
| 4 | BITMAP CONVERSION FROM ROWIDS| |
|* 5 | INDEX RANGE SCAN | COMM_CLIE_FK |
| 6 | BITMAP CONVERSION FROM ROWIDS| |
|* 7 | INDEX RANGE SCAN | COMM_EMPL_FK |
---------------------------------------------------------